前言
数字千分位分割、手机号3-3-4格式拼接、trim函数实现、HTML转义、获取url query参数...你是不是也经常在面试和工作中遇到呢?让我们一起看看,如何用正则将他们一网打尽吧!!!
1. 数字价格千分位分割
这道题估计大家在面试和工作中也经常遇到,出现频率比较高。
正则结果
分析过程
题目意思大概是:
-
从后往前
每三个数字前加一个逗号 -
开头不能加逗号(比如:
123最后不能变成,123)
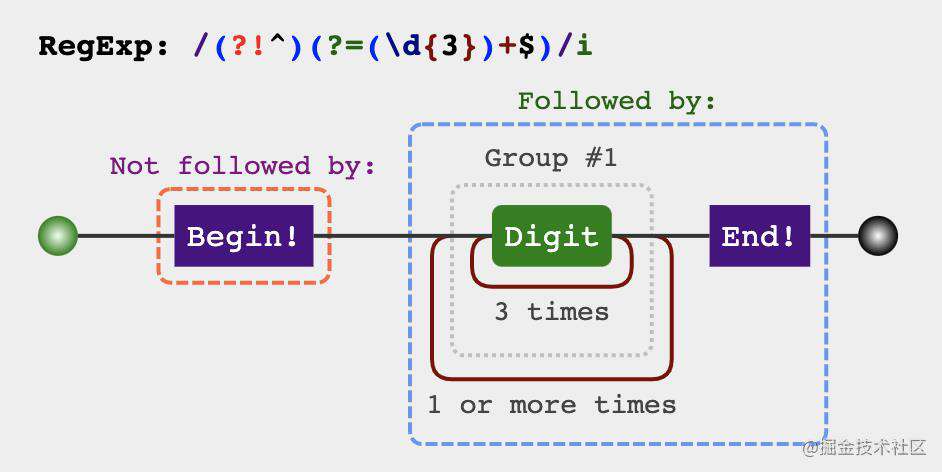
是不是很符合(?=p)的规律呢?p可以表示每三个数字,要添加的逗号所处的位置正好是(?=p)匹配出来的位置。
第一步,尝试先把后面第一个逗号弄出来
第二步,把所有的逗号都弄出来
要把所有的逗号都弄出来,主要要解决的问题是怎么表示三个数字一组,也就是3的倍数。我们知道正则中括号可以把一个p模式变成一个小整体,所以利用括号的特性,可以这样写
第三步,去掉首位的逗号,
上面已经基本上实现需求了,但是还不够,首位还会出现逗号,那怎么把首位的逗号去除呢?想想是不是有一个知识正好满足这个场景? 没错(?!p),就是他了,两者结合就是从后往前每三个数字的位置前添加逗号,但是这个位置不能是^首位。
2. 手机号3-4-4分割
表单搜集场景,经常遇到的手机格式化
正则结果
分析过程
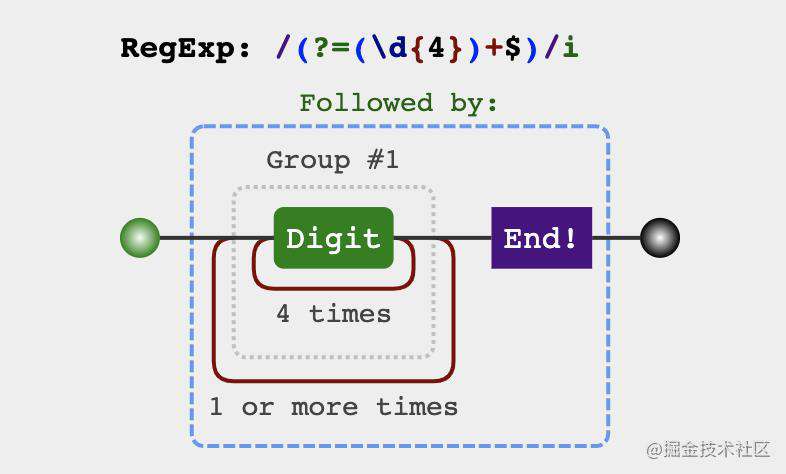
有了上面数字的千分位分割法,做这个题相信会简单很多,也就是从后往前找到这样的位置:
每四个数字前的位置,并把这个位置替换为-
3. 手机号3-4-4分割扩展
- 123 => 123
- 1234 => 123-4
- 12345 => 123-45
- 123456 => 123-456
- 1234567 => 123-4567
- 12345678 => 123-4567-8
- 123456789 => 123-4567-89
- 12345678911 => 123-4567-8911
想想这其实是我们经常遇到的用户输入手机号的过程中,需要不断格式化。
正则结果
分析过程
这里用(?=p)就不太合适了,例如1234就会变成-1234。我们需要另寻他法,
正则中还有其他的知识点方便处理这种场景吗?有 (?<=p)
第一步, 将第一个-弄出来
将第二个-弄出来
接着我们弄出来第二个,第二个-正好处于第8位(1234567-)的位置。
4。 验证密码的合法性
正则结果
分析过程
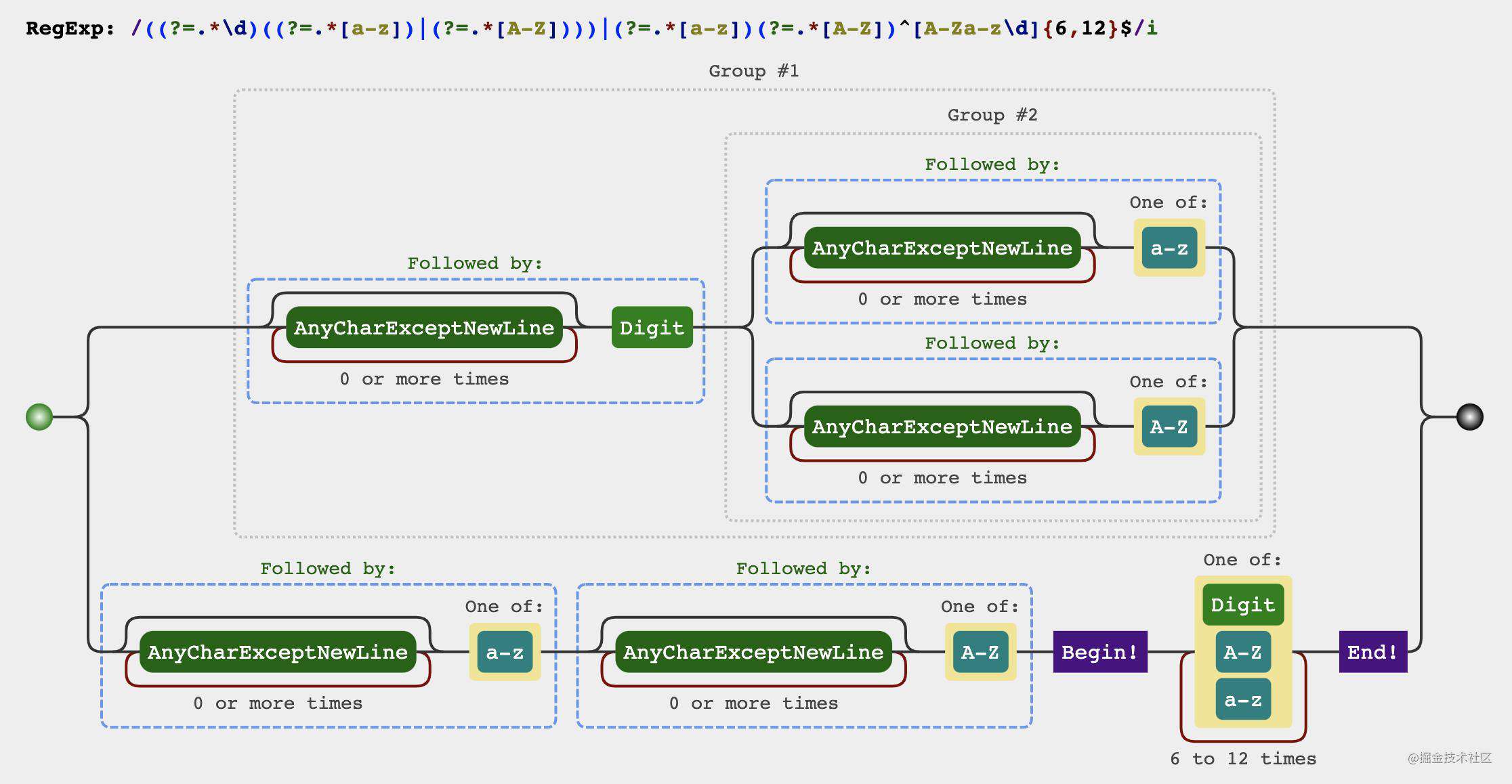
题目由三个条件组成
-
密码长度是6-12位
-
由数字、小写字符和大写字母组成
-
必须至少包括2种字符
第一步,写出条件1和2和正则
第二步,必须包含某种字符(数字、小写字母、大写字母)
第三步,写出完整的正则
必须包含两种字符,有下面四种排列组合方式
-
数字和小写字母组合
-
数字和大写字母组合
-
小写字母与大写字母组合
-
数字、小写字母、大写字母一起组合(但其实前面三种已经覆盖了第四种了)
5. 提取连续重复的字符
正则结果
分析过程
题目中有几个关键信息是
- 连续重复的字符
- 连续重复的字符数的长度是不限的(如23、45是两位、6是一位)
那什么是连续重复呢?
11是连续重复、22也是连续重复、111当然也是。也就是说某些字符X之后一定也是跟着X,就叫连续重复。如果很明确知道X是就是1,那么/11+/也就可以匹配了,但关键是这里的X是不明确的,怎么办呢?。
使用反向引用的正则知识可以很方便解决这个问题。
第一步,写出表示有一个字符重复的正则
第二步,写出表示有n个字符重复的正则
因为并不确定是要匹配11还是45 45所以括号内需要用量词+来体现n个重复字符,而反向引用本身也可以是大于一个的,例如 45 45 45
第三步,提取所有连续重复的字符
6. 实现一个trim函数
正则结果

分析过程
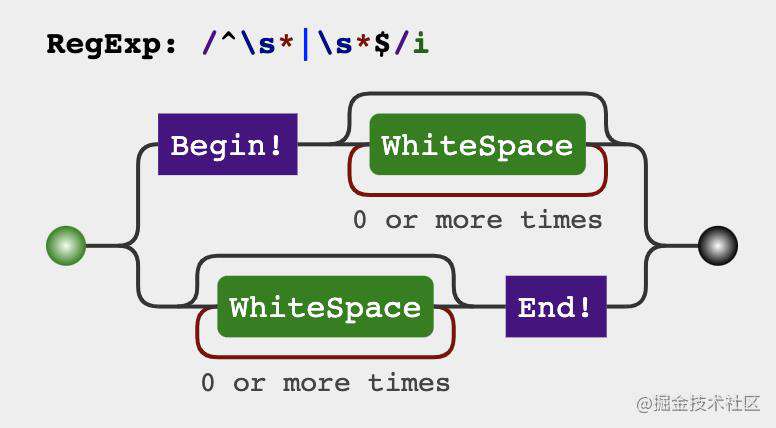
初看题目我们脑海中闪过的做法是把空格部分删除掉,保留非空格的部分,但是也可以换一种思路,也可以把非空格的部分提取出来,不管空格的部分。接下来我们来写一下两种trim方法的实现
方式一、去除空格法
方式二、提取非空格法
7. HTML转义
| 字符 | 转义后的实体 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
& | & | < | < | > | > | " | " | ' | ' |
正则结果
分析过程
全局匹配&、<、>、"、',将其按照上述表格替换就可以。类似这种某个字符可能是多种情况之一的时候,我们一般会使用字符组来做 即[&<>"']
8. HTML反转义
正则结果
反转义也就是刚才的逆过程,我们很容易写出
9. 将字符串驼峰化
正则结果
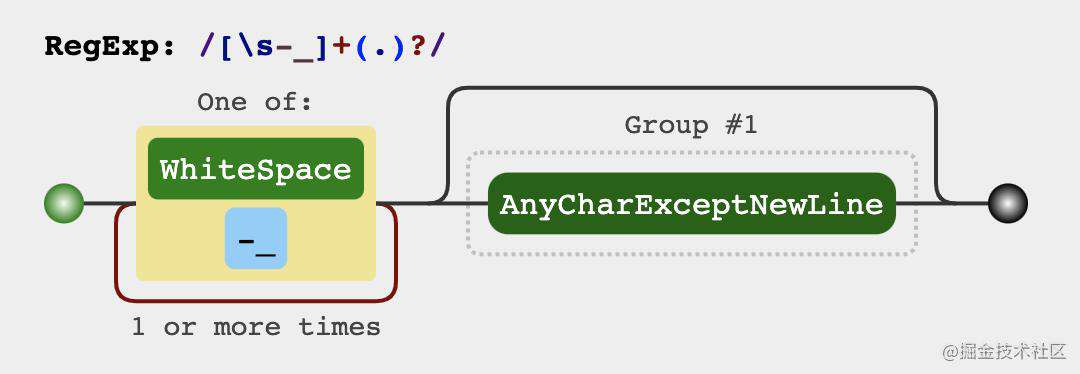
分析过程
分析题目的规律
- 每个单词的前面都有0个或者多个
-空格_如(Foo、--foo、__FOO、_BAR、Bar) -空格_后面有可能不跟任何东西 如(__、--)
10. 将字符串首字母转化为大写,剩下为小写
正则结果

分析过程
找到单词的首字母然后将其转化为大写字母就可以,单词前面可能是开头也可能是多个空格。
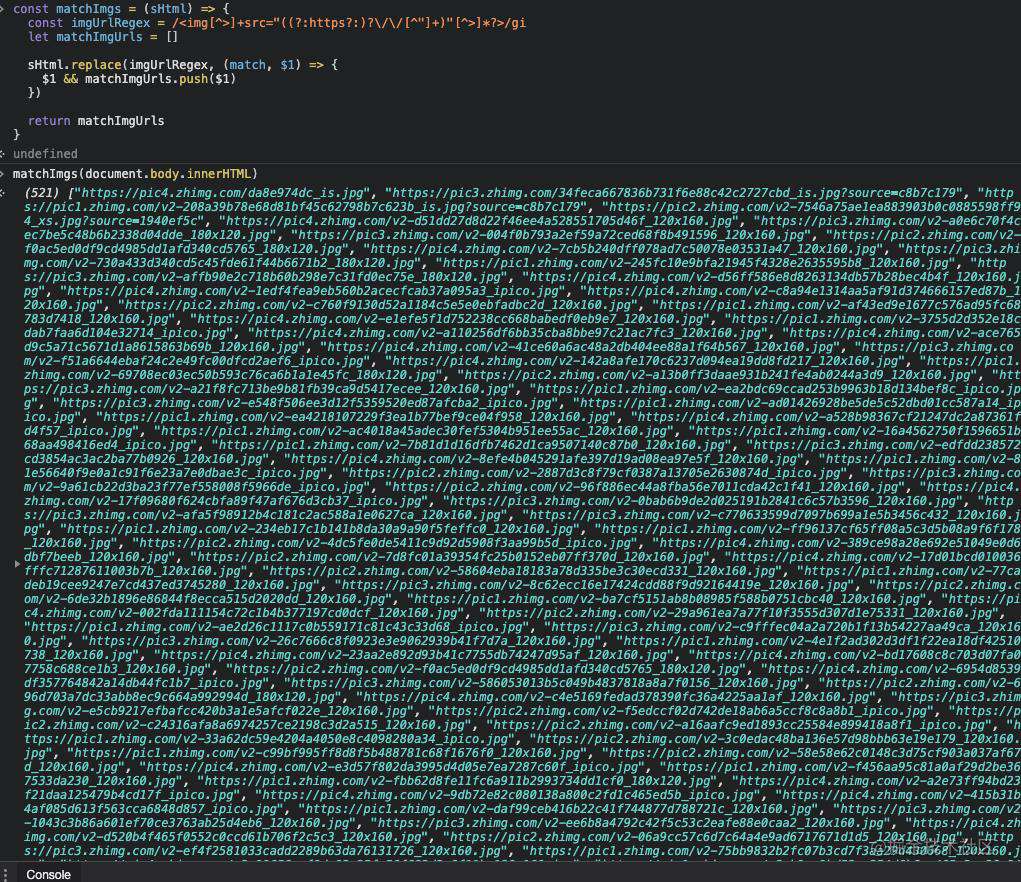
11. 获取网页中所有img标签的图片地址
分析过程
平时写过一些爬虫的同学对匹配img标签的url一定不陌生,为了准确抓取小姐姐的图片地址,一定动用了你各种聪明才智,最后也如愿以偿。
题目中限定了
- 图片标签
img - 需要是在线链接形式,一些base64的图片需要过滤掉
接下来我们直接看结果,通过可视化的形式看一下这个正则要表示的意思是啥
我们把正则分成几个部分来看
-
img标签到src之间的部分,只要不是>,其他的啥都可以
-
括号内的部分,也就是我们要提取的url部分,作为一个捕获分组存在,方便直接获取
2.1 (?:https?:)? 表示支持协议头为http:或者https:
2.2 括号外面的?,表示可以没有协议头,即支持
//xxx.juejjin.com/a.jpg形式的链接2.3 接着是两个斜线
2.4 因为src="" 双引号内的部分即为链接,所以
[^"]+表示除了"其他部分都行 -
接着就是"到img结束标签>之间的部分了,除了>之外,啥都可以
[^>]*?

试试结果
我们到知乎,打开控制台,可以看到是符合预期的。
12.通过name获取url query参数
正则结果
分析过程
url query上的参数 name=前端胖头鱼 所处的位置可能是
-
紧跟着问号?name=前端胖头鱼&sex=boy -
在最后的位置?sex=boy&name=前端胖头鱼 -
在1和2之间?sex=boy&name=前端胖头鱼&age=100
所以只要处理三个地方基本就可以通过正则来取了
- name前面只能是?或者&
- value的值可以除了是&以为的任意东西
- value后面只能是跟着&或者是结束位置
13. 匹配24小时制时间
01:141:141:123:59
正则结果
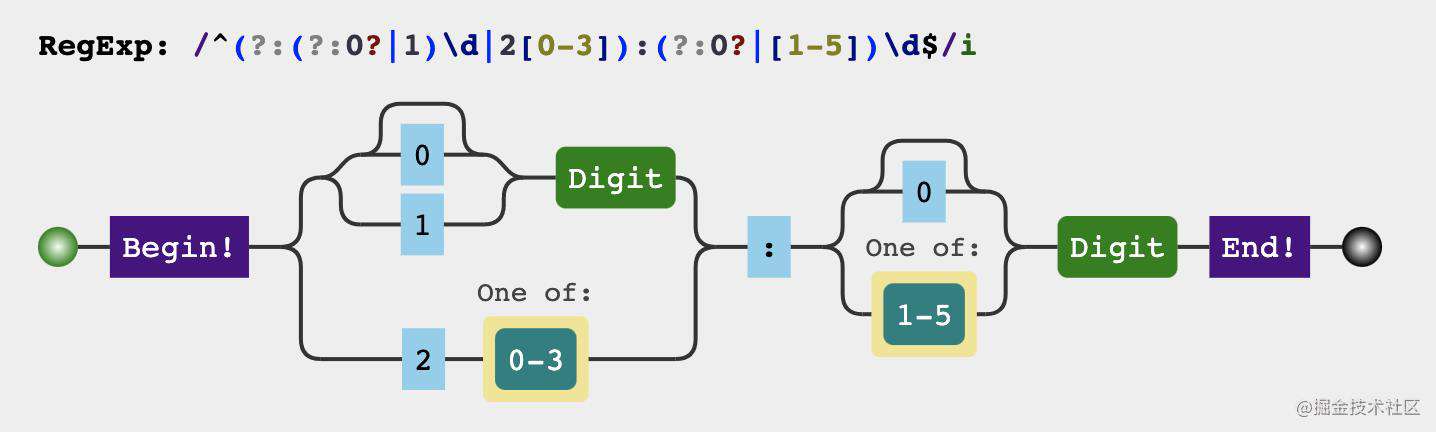
分析过程
24小时制的时间的时和分分别需要满足
时
-
第一位可以是012
-
第二位
2.1 当第一位是01时,第二位可以是任意数字
2.2 当第二位是2时,第二位只能是0、1、2、3
分
- 第一位可以是0、1、2、3、4、5
- 第二位可以是任意数字
第一步,先写出符合1和4规则的正则
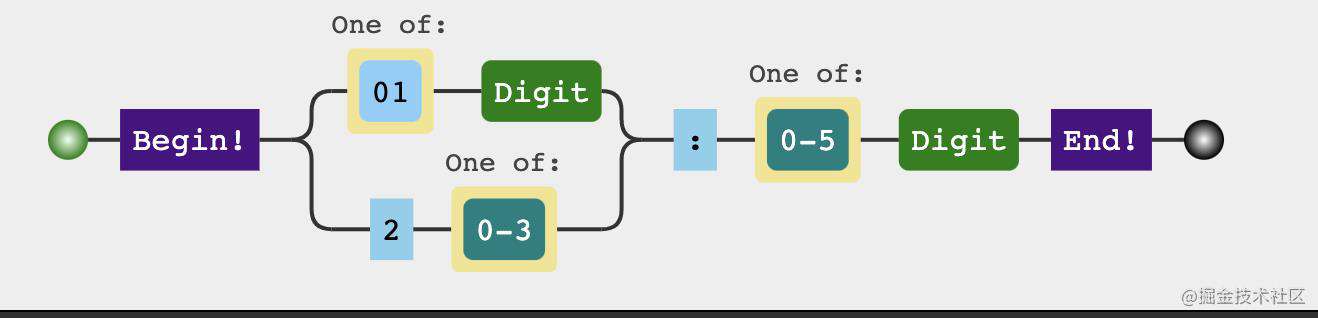
第二步,写出时和分都可以是单数的情况
14. 匹配日期格式
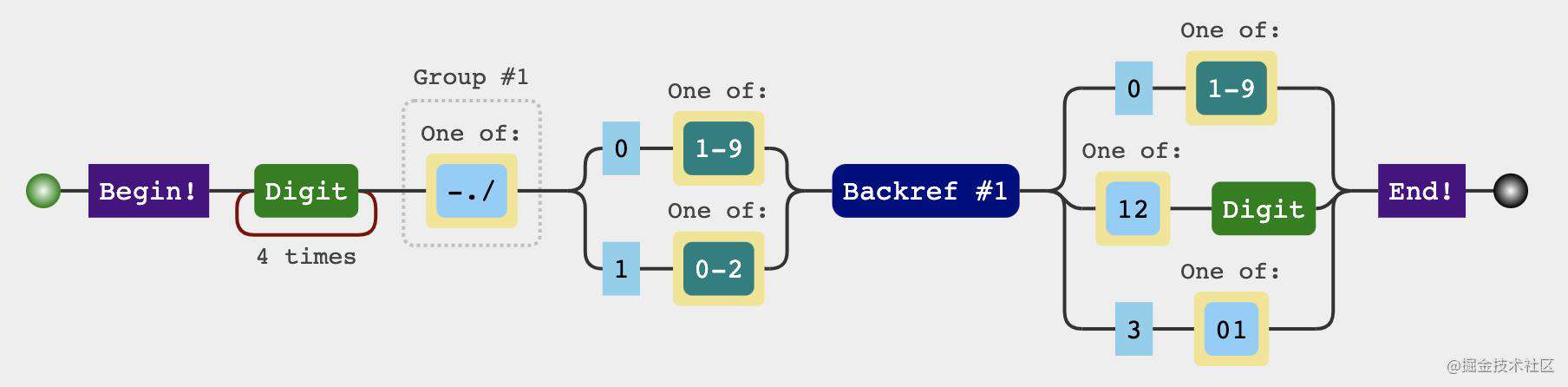
正则结果
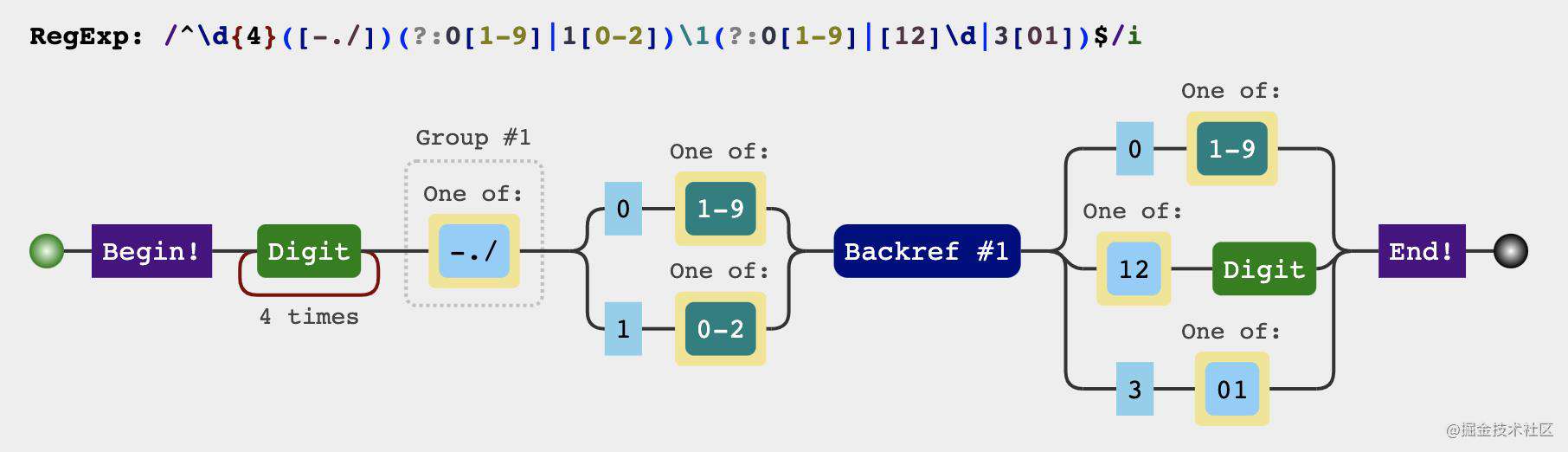
分析过程
日期格式主要分为三个部分
-
yyyy年部分这部分只要是四个数字就可以\d{4} -
mm月份部分2.1 一年只有12个月,前10个月可以用
0\d2.2 10月份及其以后以后
1[0-2] -
dd日部分3.1 一个月最多是31日
3.2 最小是1号
分隔符
需要注意的是分割符必须一样不能-./三种混用,比如2021.08-22
根据以上分析我们可以写出
可视化形式中有一个Backref #1 ,也就是反向引用第一个分组也就 ([-\.\/])、这样就保证了分割符一定是一样的
15. 匹配16进制的颜色值
正则结果
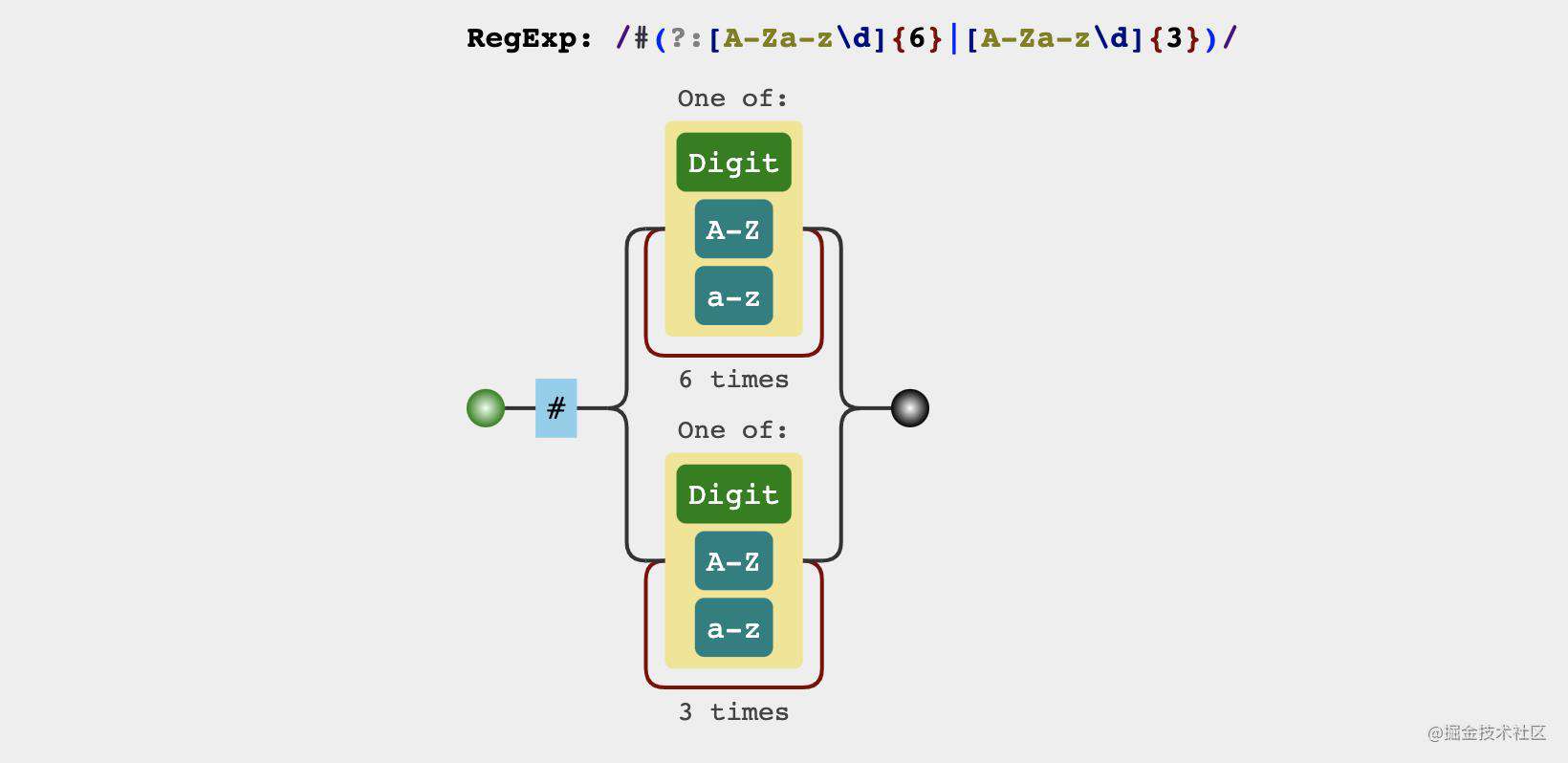
分析过程
16进制的颜色值由以下两部分组成
#- 6位或3位
数字、大小写字母组成
我们不能把正则写成/#(?:[\da-zA-Z]{3}|[\da-zA-Z]{6})/g,因为正则中的多选分支|是惰性匹配的,优先匹配前面的分支,这时候去匹配'#12f3a1 #ffBabd #FFF #123 #586',将会得到[ '#12f', '#ffB', '#FFF', '#123', '#586' ]
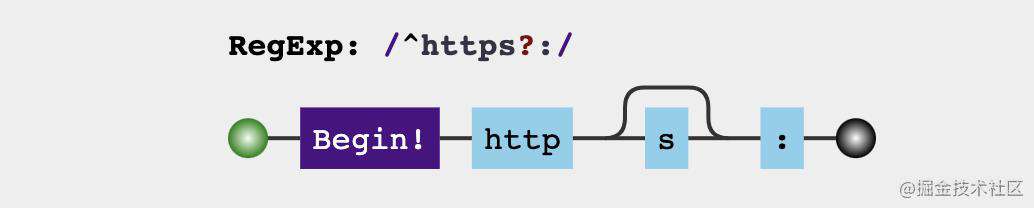
16. 检测URL前缀
这个相对简单,但是在日常工作中还是经常碰到。
正则结果
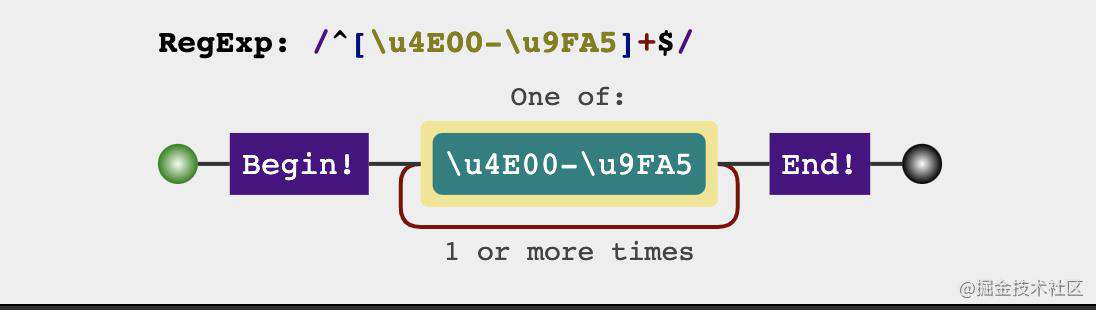
17. 检测中文
最重要是要确定中文在unicode的编码范围汉字 Unicode 编码范围,如果要加上基本汉字之外的匹配,只需要用多选分支即可
分析过程
18. 匹配手机号
时效性
手机号本身是有时效性的,各大运营商有时候会推出新的号码,所以我们的正则也具有时效性,需要及时补充
规律性
具体规律可以查看 中国大陆移动终端通信号码
解析过程
正则参考自 ChinaMobilePhoneNumberRegex
当遇到一个很长看起来很复杂的正则的时候,有什么好办法可以让我们看懂它?
可以借助可视化工具辅助我们拆解正则。
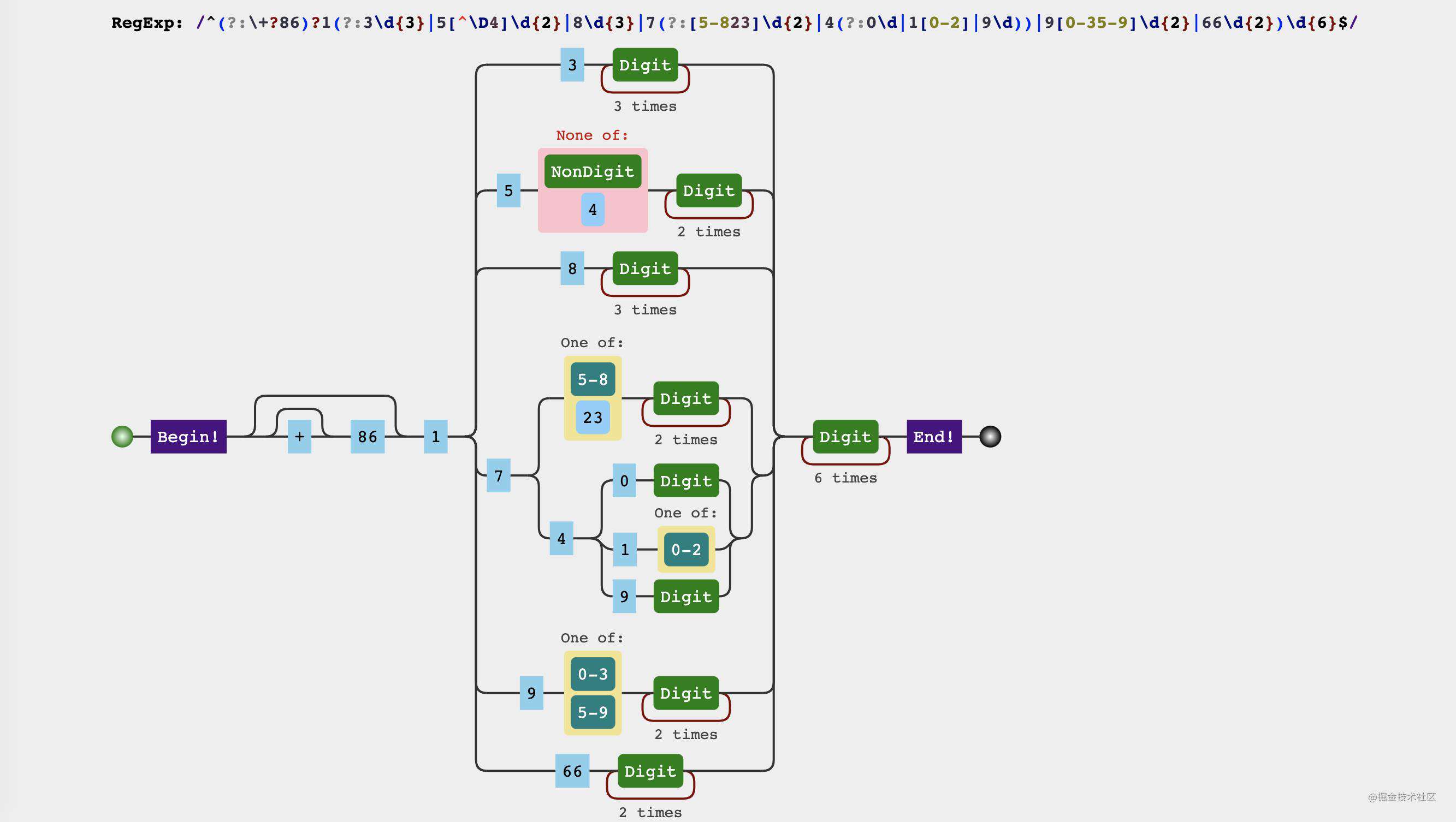
所以mobileRegex可以分成以下几个部分
(?:\+?86)?: 手机前缀,括号内通过?:标识非引用分组- 1: 所有的手机号都是以1开头
- (a|b|c|...): 2~5位的各种情况,通过多选分支|进行逐一解释
- \d{6}: 6位任意数字
拆解开来后会发现其实也不复杂,只是第三部分因为可能性太多了,用了好多多选分支来说明,只要理清楚了手机号规则,每个分组里面的规律也就不难了。
19. 英文单词加前后空格
如:you说来是come,去是go => you 说来是 come ,去是 go 例子
解析过程
这里只要了解正则中\b位置的概念就可以了,\b的意思是单词的边界,具体讲有三点规则
-
\w和\W之间的位置
-
^与\w之间的位置
-
\w与$之间的位置
所以:
第一个单词you,符合规则2、
第二个单词come,符合规则1、
第三个单词符合go,符合规则3
20. 字符串大小写取反
解析过程
这题比较容易想到的是通过ASCII码确定大小写,然后再转成对应的值即可,但是既然是正则的总结,我们就尝试一下通过正则来完成。
不通过ASCII码那如何确定一个字符是否是大写呢?其实只要将他变成了大写字符,再与元字符比较一下,相等那说明远字符也是大写的。比如
所以题目可以这样写
21. windows下的文件夹和文件路径
-
C:\Documents\Newsletters\Summer2018.pdf
-
C:\Documents\Newsletters\
-
C:\Documents\Newsletters
-
C:\
正则结果
解析过程
windows下的文件规则大概由这几部分构成
磁盘符:\文件夹\文件夹\文件
-
磁盘符:只能是英文构成
[a-zA_Z]:\\ -
文件夹名字:不包含一些特殊符号且可出现任意次,最后的\可以没有
([^\\:*<>|"?\r\n/]+\\?)* -
文件名字:
([^\\:*<>|"?\r\n/]+)\.\w+,但是文件可以没有

22. 匹配id(写爬虫获取html经常用到)
正则结果
解析过程
写爬虫的过程中经常需要匹配指定条件的dom元素,然后再去做对应的操作。那么怎么获取box呢
相信大家最先想到的是这个正则id="(.*)"
但是id="(.*)"很容易导致回溯,从而耗费更多的匹配时间。有什么优化的方式吗?
是的只需要将.换成[^"]即可,当遇到"时,正则即认为匹配结束,也就不会发生回溯了。
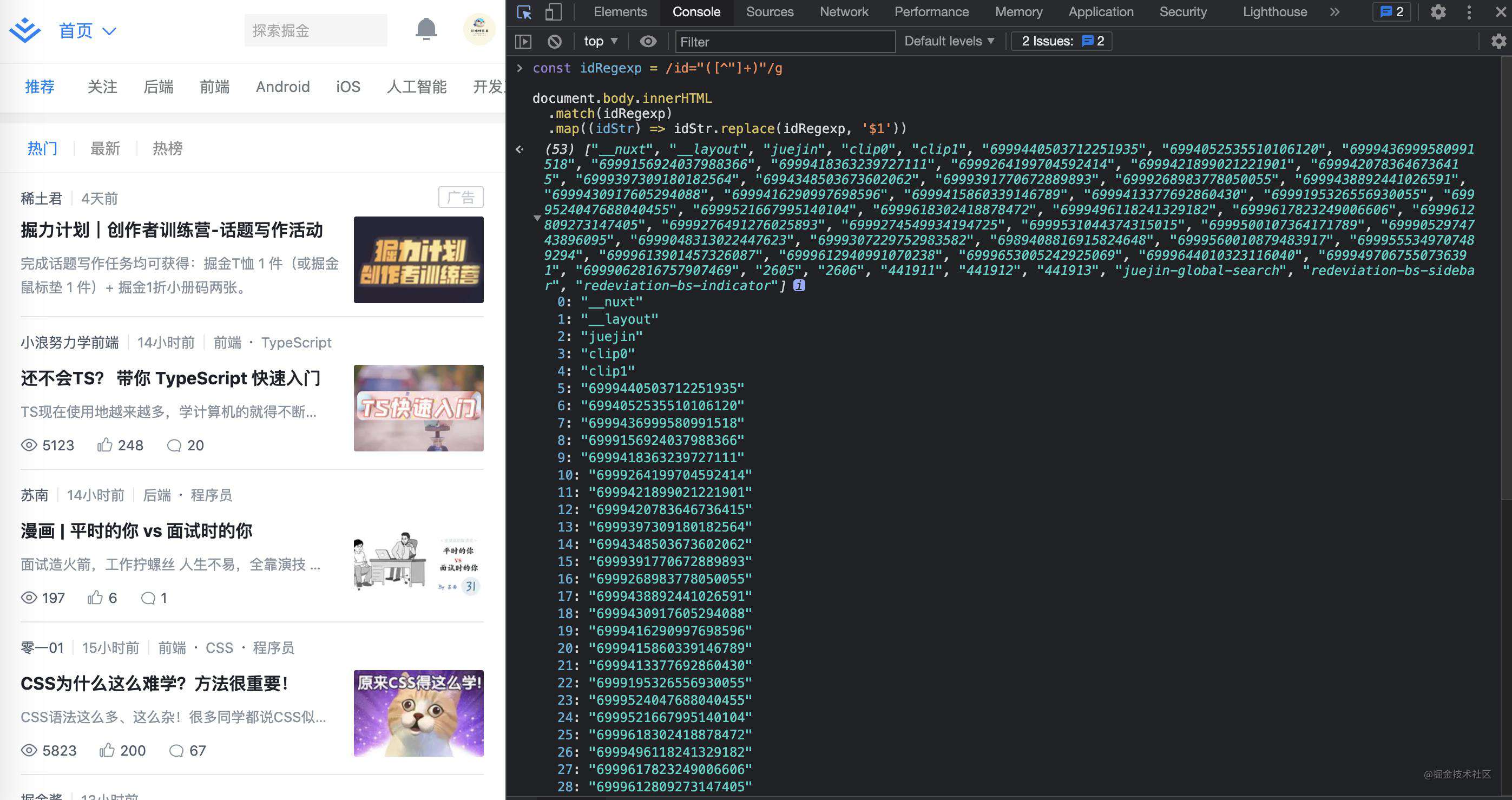
23. 匹配id 扩展(获取掘金首页html所有id)
正则结果
24. 大于等于0, 小于等于150, 支持小数位出现5, 如145.5, 用于判断考卷分数
正则结果
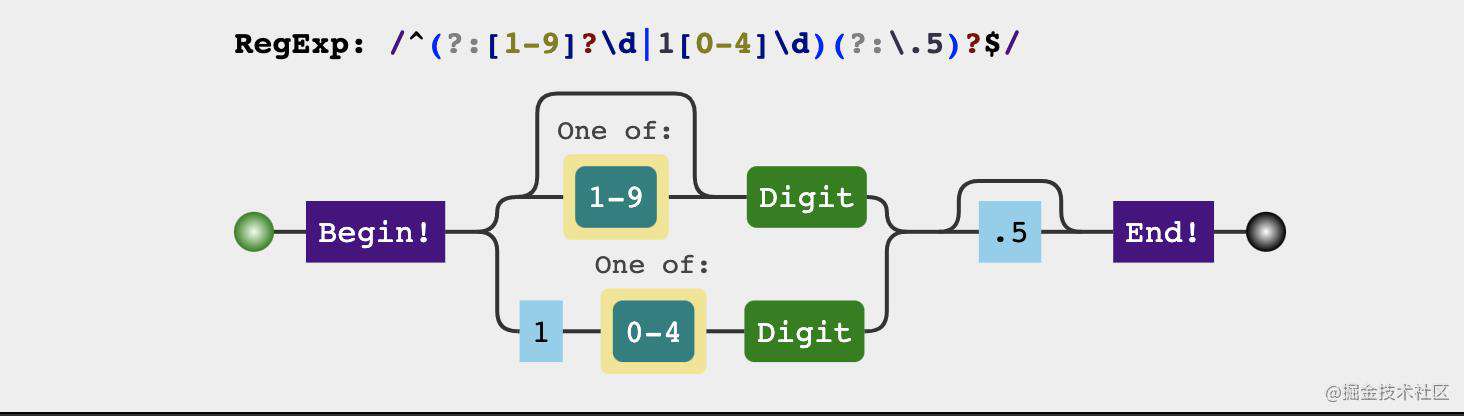
分析过程
我们可以将这道题分成两部分看
-
整数部分
- 个位整数
- 十位整数
- 百位整数但小于150
-
小数部分:只能是
.5或者没有
先尝试写整数部分
再加上小数部分
25. 判断版本号
正则结果
相约再见
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!