
包含表格、图表和图形的Web应用程序通常包含将数据导出为PDF的选项。你有没有想过,作为一个用户,当你点击那个按钮时,幕后发生了什么?
作为开发人员,如何让PDF输出看起来更专业?大多数免费的在线PDF导出器实际上只是将HTML内容转换为PDF,而不进行任何额外的格式化,这会使数据难以阅读。如果你也能添加诸如页眉和页脚、页码或重复的表列标题等内容呢?像这样的小点缀,对把一份看起来很业余的文件变成一份优雅的文件有很大的帮助。
最近,我探索了几种生成PDF的解决方案,并建立了这个Demo程序来展示结果。所有的代码也可以在Github上找到。让我们开始吧!
Demo程序概述
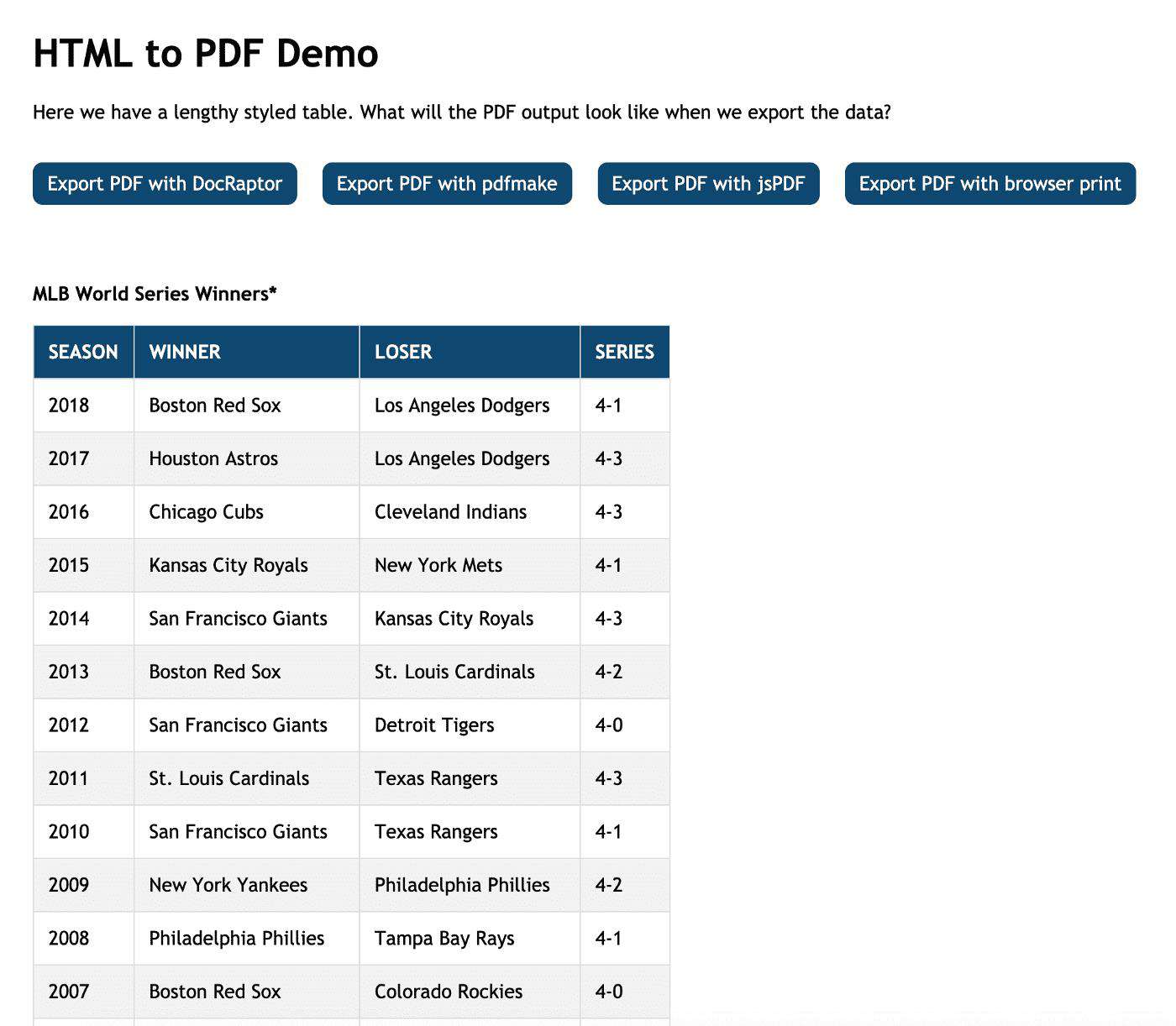
我们的Demo程序包含一个冗长的样式表和四个将表导出为PDF的按钮。该应用是用基本的HTML、CSS和JavaScript构建的,但你可以使用你的UI框架或选择的库轻松创建相同的输出。
每个导出按钮都使用不同的方法生成PDF。从右到左查看,第一个使用原生浏览器打印功能,第二个使用名为jsPDF的开源库,第三个使用另一个名为pdfmake的开源库,最后,第四个使用名为DocRaptor的付费服务。
让我们一一探讨每个解决方案。
原生浏览器打印功能
首先,我们考虑使用浏览器的内置工具导出PDF。在查看任何网页时,你可以通过右键单击任意位置,然后从菜单中选择“打印”选项来轻松地打印页面。这将打开一个对话框,供你选择打印设置。但是,你实际上不必打印文档。对话框还提供了将文档保存为PDF的选项,这就是我们要做的。在JavaScript中 window 对象公开了一个 print 方法,所以我们可以写一个简单的JavaScript函数,并将其附加到我们的一个按钮上,就像这样:
function downloadPDFWithBrowserPrint() {
window.print();
}
document.querySelector('#browserPrint').addEventListener('click', downloadPDFWithBrowserPrint);
以下是Google Chrome浏览器的输出:
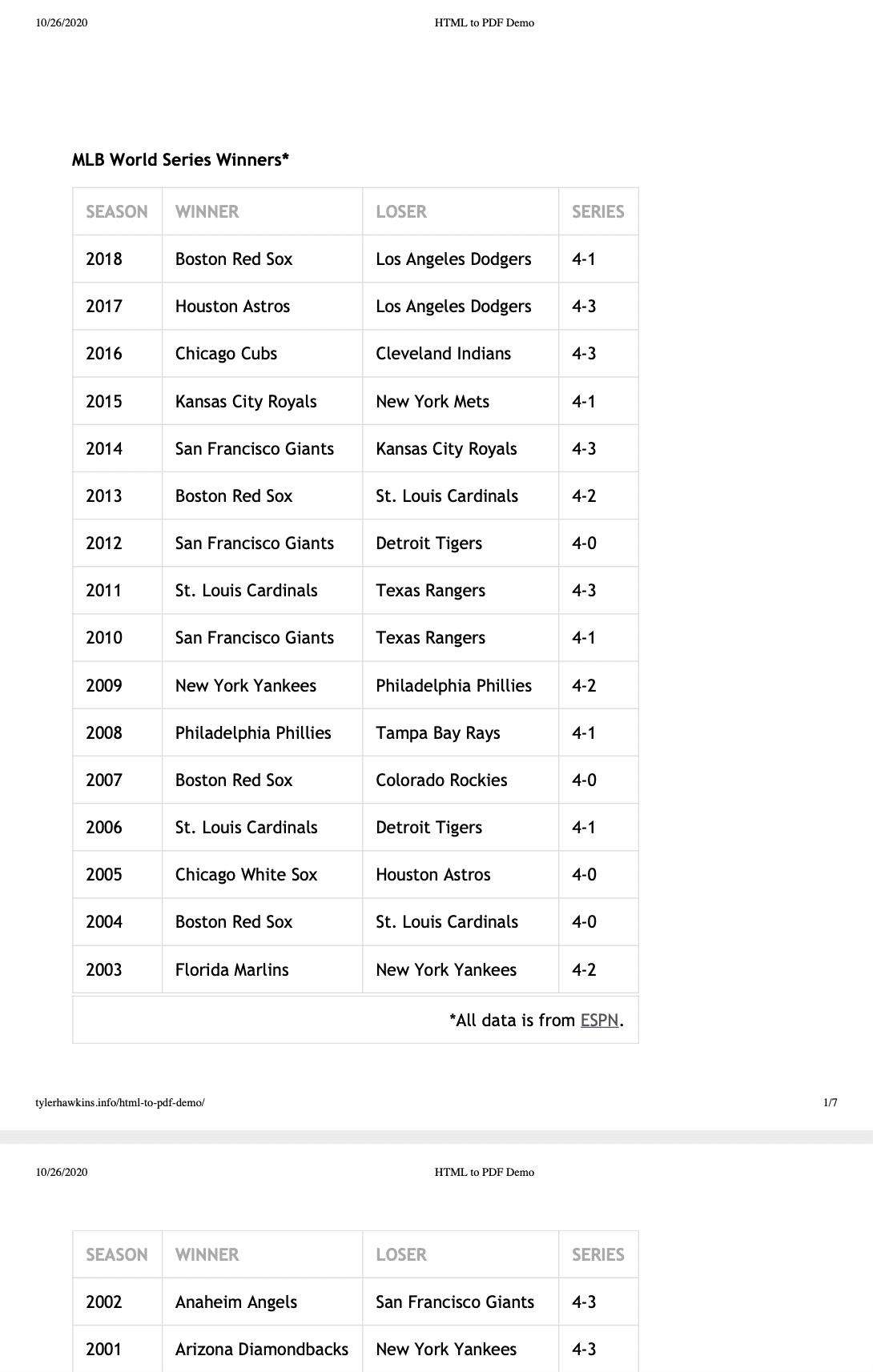
我对这里的输出感到惊喜,虽然它并不华丽——内容只是黑白色的,但主要的表格样式却被完整地保留了下来。此外,这七个页面中的每一个都包含表列标题和页脚,我认为浏览器可以智能地获取这些信息,这是由于我在构建结构合理的表时选择了语义HTML。
然而,我不喜欢浏览器在PDF中包含的额外页面元数据。靠近顶部,我们看到日期和HTML页面标题。在页面的底部,我们看到了打印这篇文章的网站以及页码。
如果我保存这个文档的唯一目的是为了看数据,那么Chrome浏览器做得很好。不过,文档顶部和底部多出的几行文字虽然有用,但并没有让它看起来很专业。
另外需要注意的是,不同浏览器的原生打印功能是不一样的。如果我们用Safari浏览器打印同样的文档呢?输出如下:
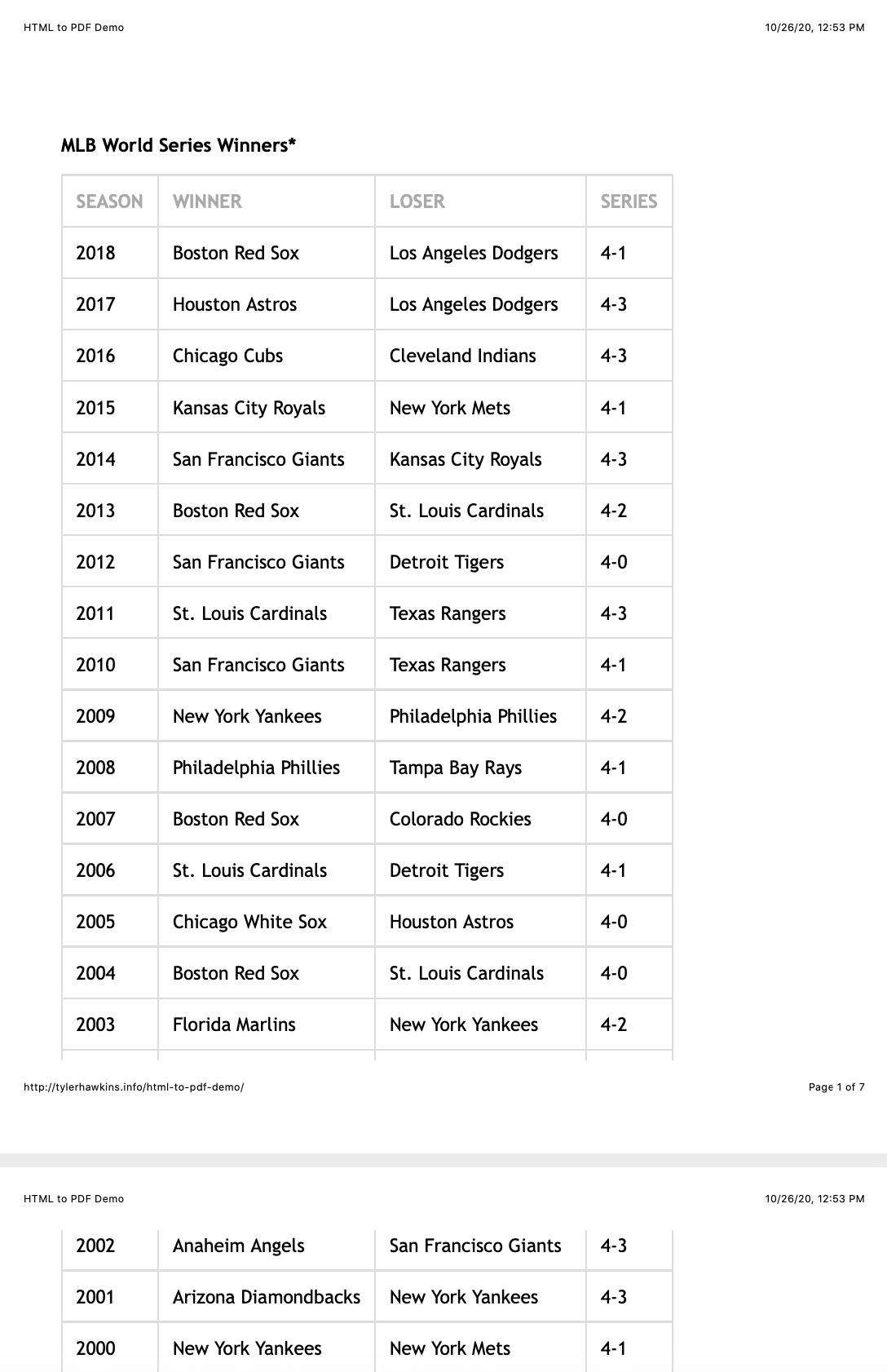
你会注意到表格看起来大致相同,页面页眉和页脚内容也是如此。但是,表列标题和表脚不重复!这是没有帮助的,因为当你忘记任何给定列包含什么数据时,你需要返回到第一页。第一页的表格底部也有点被切断,因为浏览器试图在创建下一页之前尽可能多地挤进内容。
如此看来,浏览器的输出并不理想,会因用户选择的浏览器不同而不同。
jsPDF
接下来让我们考虑一个名为jsPDF的开源库。这个库已经存在了至少5年,每周从NPM的下载量持续超过20万次。可以说这是一个很受欢迎的、经过实战检验的库。
jsPDF的使用也相当简单。你可以创建一个新的jsPDF类的实例,给它一个你想导出的HTML内容的引用,然后提供任何其他附加的设置,如页边距大小或文档标题。
function downloadPDFWithjsPDF() {
var doc = new jspdf.jsPDF('p', 'pt', 'a4');
doc.html(document.querySelector('#styledTable'), {
callback: function (doc) {
doc.save('MLB World Series Winners.pdf');
},
margin: [60, 60, 60, 60],
x: 32,
y: 32,
});
}
document.querySelector('#jsPDF').addEventListener('click', downloadPDFWithjsPDF);
在内部,jsPDF使用了一个名为html2canvas.的库。顾名思义,html2canvas 接收 HTML 内容,并将其转化为存储在 HTML <canvas> 元素上的图像,然后 jsPDF 接收该画布内容并将其保存。
让我们看一下使用jsPDF的输出:
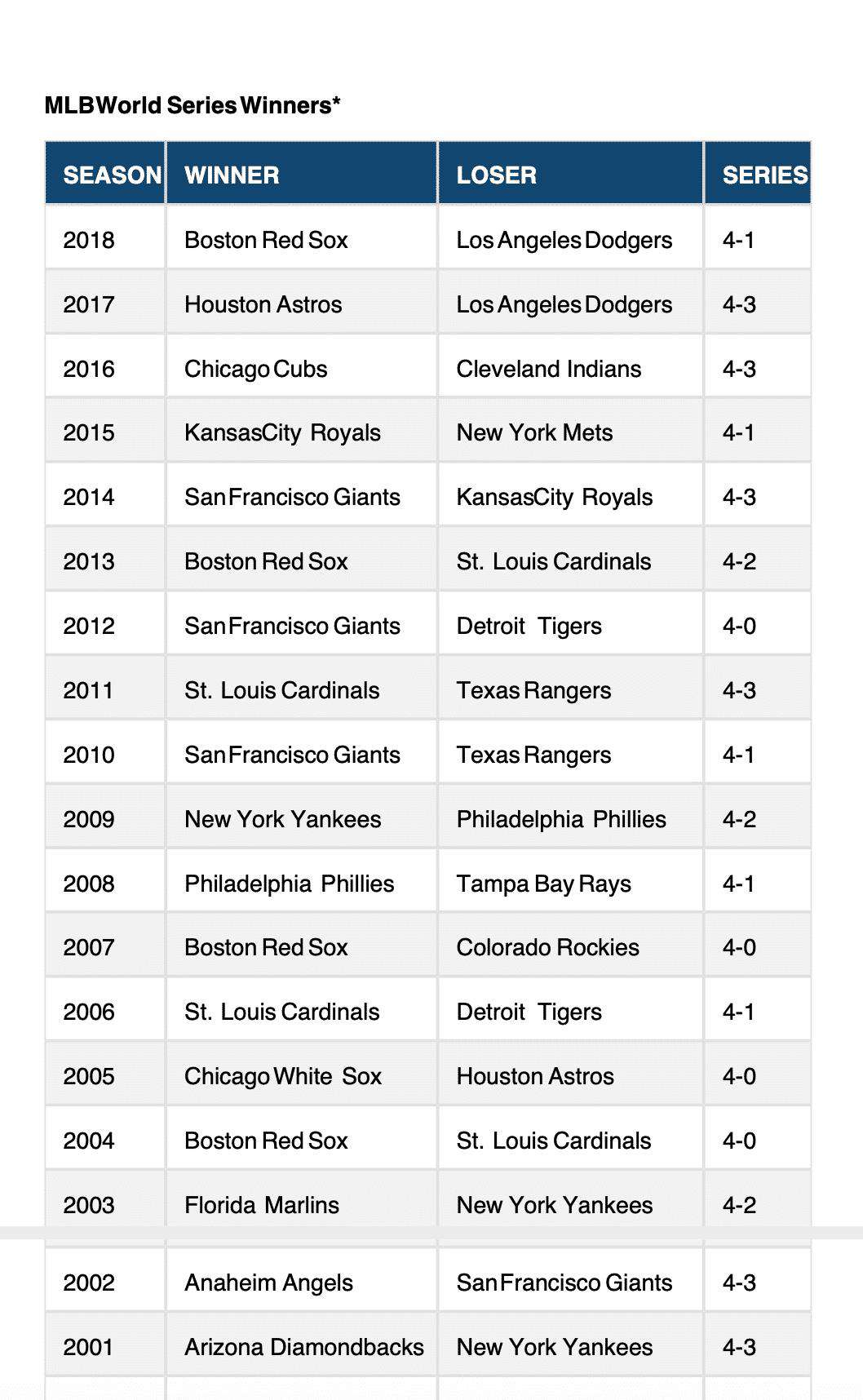
乍一看,这看起来还不错! PDF包含我们漂亮的蓝色标题和条纹表行背景。它不包含浏览器打印方法所包含的任何多余页面元数据。
但是,请注意在第一页和第二页之间发生了什么。表格一直延伸到第一页的底部,然后在第二页的顶部直接接上。没有应用额外的边距,而且表文本内容有可能被切成两半。
该PDF也不包括重复的表列标题或表脚,这与我们在Safari的打印功能中看到的问题相同。
虽然jsPDF是一个强大的库,但当导出的内容只能容纳在一个页面上时,这个工具似乎效果最好。
pdfmake
让我们看一下我们的第二个开源库pdfmake。NPM每周下载量超过30万次,寿命长达7年,这个库甚至比jsPDF更受欢迎,更资深。
在为我的demo程序构建导出功能时,pdfmake的配置要比jsPDF难得多。原因是pdfmake使用你提供的数据从头开始构建PDF文档,而不是将页面上现有的HTML内容转换为PDF。这意味着,我必须为它提供PDF表格的页眉、页脚、内容和布局的数据,而不是为pdfmake提供一个对我的HTML表格的引用。这导致我的代码有很多重复,我先在HTML中写了表格,然后用pdfmake为PDF导出重新建表。
代码如下:
function downloadPDFWithPDFMake() {
var tableHeaderText = [...document.querySelectorAll('#styledTable thead tr th')].map(thElement => ({ text: thElement.textContent, style: 'tableHeader' }));
var tableRowCells = [...document.querySelectorAll('#styledTable tbody tr td')].map(tdElement => ({ text: tdElement.textContent, style: 'tableData' }));
var tableDataAsRows = tableRowCells.reduce((rows, cellData, index) => {
if (index % 4 === 0) {
rows.push([]);
}
rows[rows.length - 1].push(cellData);
return rows;
}, []);
var docDefinition = {
header: { text: 'MLB World Series Winners', alignment: 'center' },
footer: function(currentPage, pageCount) { return ({ text: `Page ${currentPage} of ${pageCount}`, alignment: 'center' }); },
content: [
{
style: 'tableExample',
table: {
headerRows: 1,
body: [
tableHeaderText,
...tableDataAsRows,
]
},
layout: {
fillColor: function(rowIndex) {
if (rowIndex === 0) {
return '#0f4871';
}
return (rowIndex % 2 === 0) ? '#f2f2f2' : null;
}
},
},
],
styles: {
tableExample: {
margin: [0, 20, 0, 80],
},
tableHeader: {
margin: 12,
color: 'white',
},
tableData: {
margin: 12,
},
},
};
pdfMake.createPdf(docDefinition).download('MLB World Series Winners');
}
document.querySelector('#pdfmake').addEventListener('click', downloadPDFWithPDFMake);
在我们完全否定pdfmake之前,我们先来看看输出。
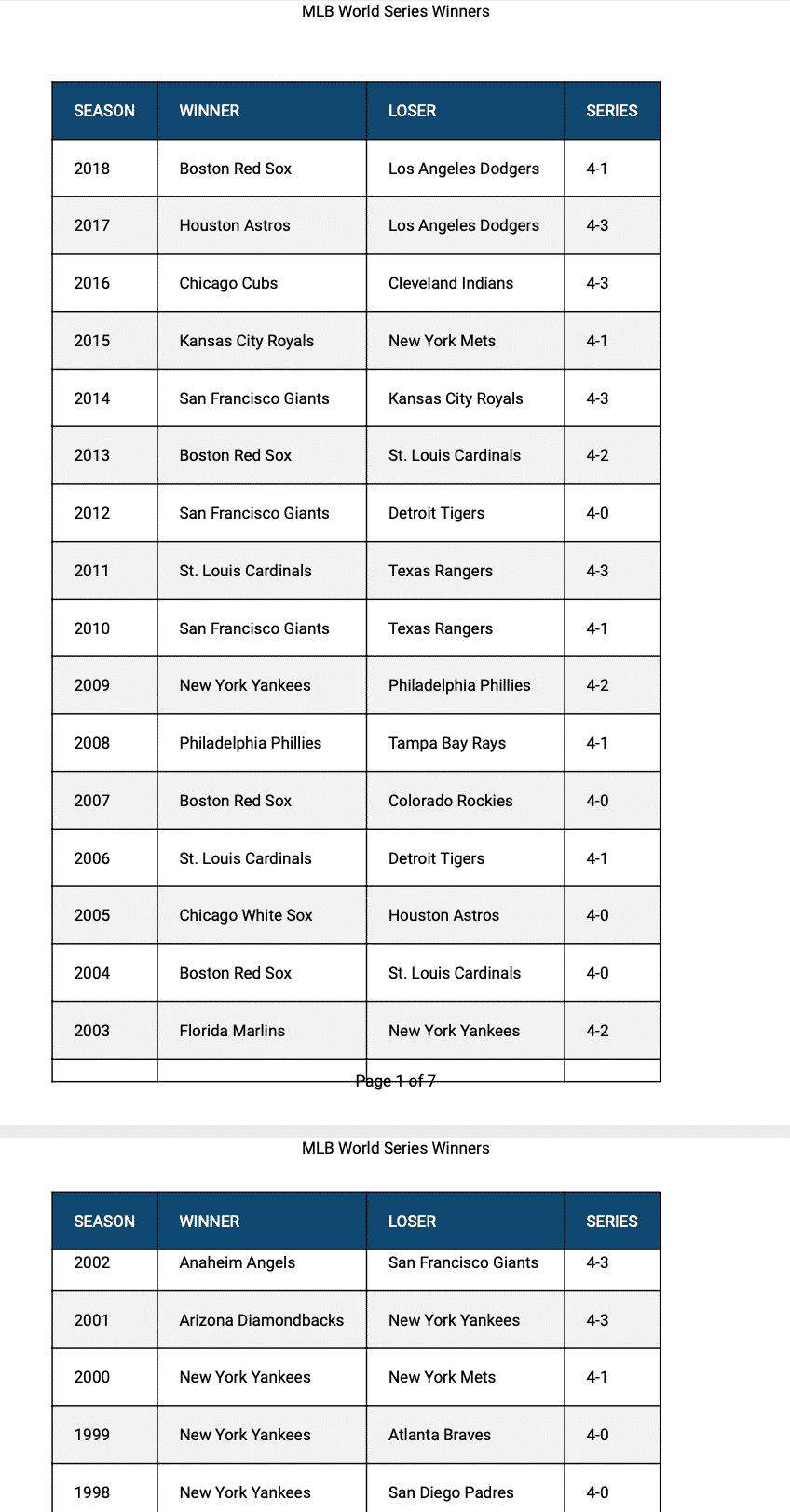
不是太寒酸!我们可以为表包含样式,这样我们仍然可以复制蓝色列标题和条纹表行背景。我们还得到了重复的表列标题,以便于跟踪我们在每个页面的每个列中看到的数据。
pdfmake还允许我加入页眉和页脚,所以很容易添加页码。但你会注意到,第一页和第二页之间的表格内容仍然没有完全分开。分页符将2002年的一行部分地分割在两页之间。
总体看来,pdfmake最大的优势在于从头开始构建PDF。例如,如果你想根据某些订单数据生成发票,而你实际上并没有在web应用程序的页面上显示发票,那么pdfmake将是一个很好的选择。
DocRaptor
最后一个我们要考虑的选项是DocRaptor。DocRaptor与我们探讨的前三个选项不同的是,它是一种付费服务。它使用Prince HTML-to-PDF引擎来生成其PDF输出。该服务也通过API使用,因此你的代码会碰到一个外部API端点,然后该端点会返回PDF文档。

DocRaptor的基本配置相当简单,你向它提供你的文档名称,你要创建的文档类型(在我们的例子中是 ’pdf'),以及要使用的HTML内容。根据你的需要,还有数百种不同配置的选择,但基本配置是一个很好的起点。
这是我使用的:
function downloadPDFWithDocRaptor() {
DocRaptor.createAndDownloadDoc('YOUR_API_KEY_HERE', {
test: true, // test documents are free, but watermarked
type: 'pdf',
name: 'MLB World Series Winners',
document_content: document.querySelector('html').innerHTML,
})
}
document.querySelector('#docRaptor').addEventListener('click', downloadPDFWithDocRaptor);
让我们看一下DocRaptor生成的PDF导出:
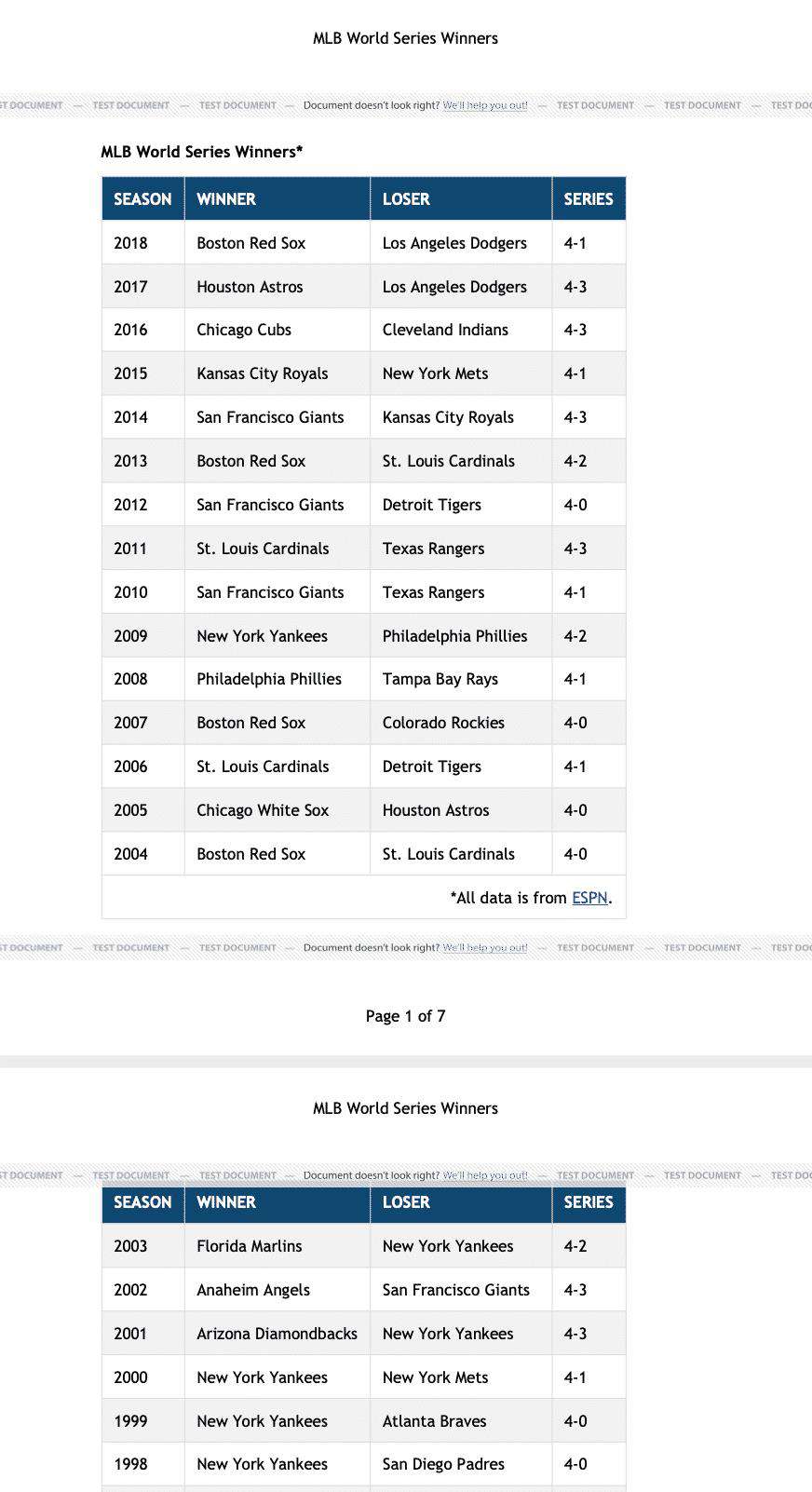
现在有一个好看的文档了! 我们可以保留我们漂亮的表格样式。表格的列头和表脚在每一页上都是重复的,表格的行数不会被切掉,而且页面四面都有适当大小的边距,每个页面的页眉也是重复的,每个页面底部的页码也是重复的。
要创建页眉和页脚文本,DocRaptor建议你使用一些CSS与 @page 选择器,就像这样。
@page {
margin-top: 80px;
margin-bottom: 80px;
@top {
content: "MLB World Series Winners"
}
@bottom {
/* 具有计数器功能的页脚可插入页面计数器 */
content: "Page " counter(page) " of " counter(pages)
}
}
在PDF输出方面,DocRaptor无疑是赢家。
总结
那么,你的应用要选择哪种方案呢?如果你想要最简单的解决方案,而且不需要专业的文档,那么原生浏览器的打印功能应该就可以了。如果你需要对PDF输出进行更多的控制,那么你就需要使用一个库。
当涉及到基于UI中显示的HTML生成的单页内容时,jsPDF就会大放异彩。pdfmake在从数据而不是HTML中生成PDF内容时效果最好。DocRaptor是其中功能最强大的一款,它拥有简单的API和漂亮的PDF输出。但同样,与其他不同的是,它是一项付费服务。然而,如果你的业务依赖于优雅、专业的文档生成,DocRaptor是非常值得的。
来源:levelup.gitconnected.com/
作者:Tyler Hawkins
最近整理了一份优质视频教程资源,想要的可以扫下面的二维码关注公众号,然后在对话框中发送“666”即可免费领取哦!

常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?




发表评论
还没有评论,快来抢沙发吧!